
Introduction
KubeVela is a modern application delivery system hosted by the CNCF Foundation. It is built on the Open Application Model (OAM) specification and aims to abstract the complexity of Kubernetes, providing a set of simple and easy-to-use command-line tools and APIs for developers to deploy and operate cloud-native applications without worrying about the underlying details.
KCL is a configuration and policy language for cloud-native scenarios, hosted by the CNCF Foundation. It aims to improve the writing of complex configurations, such as cloud-native Kubernetes configurations, using mature programming language techniques and practices. KCL focuses on building better modularity, scalability, and stability around configuration, as well as easier logic writing, automation, and integration with the toolchain.
KCL exists in a completely open cloud-native world and is not tied to any orchestration/engine tools or Kubernetes controllers. It can provide API abstraction, composition, and validation capabilities for both Kubernetes clients and runtime.
Users can choose suitable cloud-native tools such as Kubectl, Helm, Kustomize, KPT, KusionStack, KubeVela, Helmfile, Crossplane, or ArgoCD to combine with KCL and apply configurations to the cluster based on their specific scenarios.

This blog is the first in a series that explores the efficient deployment and operation of cloud-native applications using KCL and KubeVela together. We will share more advanced usage in future articles, so stay tuned.
Using KCL with KubeVela
Using KCL with KubeVela has the following benefits:
- Simpler configuration: KCL provides stronger templating capabilities, such as conditions and loops, for KubeVela OAM configurations at the client level, reducing the need for repetitive YAML writing. At the same time, the reuse of KCL model libraries and toolchains enhances the experience and management efficiency of configuration and policy writing.
- Better maintainability: KCL provides a configuration file structure that is more conducive to version control and team collaboration, instead of relying solely on YAML. When combined with OAM application models written in KCL, application configurations become easier to maintain and iterate.
- Simplified operations: By combining the simplicity of KCL configurations with the ease of use of KubeVela, daily operational tasks such as deploying, updating, scaling, or rolling back applications can be simplified. Developers can focus more on the applications themselves rather than the tedious details of the deployment process.
- Improved cross-team collaboration: By using KCL's configuration chunk writing and package management capabilities in conjunction with KubeVela, clearer boundaries can be defined, allowing different teams (such as development, testing, and operations teams) to collaborate systematically. Each team can focus on tasks within their scope of responsibility, delivering, sharing, and reusing their own configurations without worrying about other aspects.
Workflow
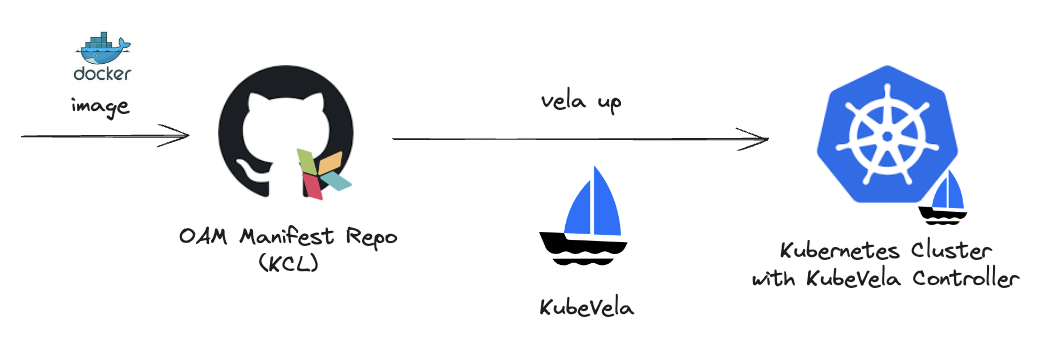
In this example, we use the KCL Playground application (written in Go and HTML5) as an example and use KCL to define the OAM configuration that needs to be deployed. The overall workflow is as follows:
- Application code development produces a Docker image.
- Write OAM configurations using KCL.
- Deploy configurations using KubeVela.
- Verify the running status of the application.
Specific Steps
0. Prerequisites
- Familiarize yourself with basic Unix/Linux commands.
- Familiarize yourself with using Git.
- Understand the basics of Kubernetes.
- Understand KubeVela.
- Understand the basics of KCL.
1. Configure the Kubernetes Cluster
Install K3d and create a cluster.
k3d cluster create
Note: You can use other methods to create your own Kubernetes cluster, such as kind, minikube, etc., in this scenario.
2. Install KubeVela
- Install the KubeVela CLI.
curl -fsSl https://kubevela.net/script/install.sh | bash
- Install KubeVela Core.
vela install
3. Write OAM Configurations
- Install KCL.
curl -fsSL https://kcl-lang.io/script/install-cli.sh | /bin/bash
- Create a new project and add OAM dependencies.
kcl mod init kcl-play-svc && cd kcl-play-svc && kcl mod add oam
- Write the following code in main.k.
import oam
oam.Application {
metadata.name = "kcl-play-svc"
spec.components = [{
name = metadata.name
type = "webservice"
properties = {
image = "kcllang/kcl:v0.9.0"
ports = [{port = 80, expose = True}]
cmd = ["kcl", "play"]
}
}]
}
Note: You can see documents here: https://artifacthub.io/packages/kcl/kcl-module/oam or in the IDE extension.
4. Deploy the application and verify.
- Apply the configuration.
kcl run | vela up -f -
- Port forward the service.
vela port-forward kcl-play-svc
Then we can see the KCL Playground application running successfully in the browser.
Conclusion
Through this guide, we have learned how to deploy cloud-native applications using KubeVela and KCL. In future blogs, we will explain how to further extend the capabilities of KubeVela by using KCL on the client side such as
- Using the inheritance, composition, and validation capabilities of KCL to extend the OAM model and define application abstractions that are better suited to your infrastructure or organization.
- Using the modularized configuration capabilities of KCL to organize OAM multi-environment configurations with conditions, logic, loops, and modularity. For example, distribute longer App Definitions into different files to reduce boilerplate configurations.
- Further integration with projects like KusionStack and ArgoCD to achieve better GitOps.
- Incorporate more cloud-native capabilities or Kubernetes Operators such as KubeBlocks and Crossplane to improve database management and provide programmable access to unified cloud APIs and Kubernetes APIs.
- And many other use cases...