Introduction
With the development of cloud-native technologies, we are increasingly shifting towards cloud infrastructure. Tools such as Kubernetes and Terraform have become increasingly popular for managing and deploying applications based on cloud APIs. However, along with this popularity, the complexity and cognitive burden associated with these tools have reached a peak in recent years.

The increasing complexity of Kubernetes and cloud APIs can be attributed to several factors:
- Growing functionality and capabilities: Kubernetes and cloud APIs continuously evolve to meet the growing demands of applications and the development of cloud computing. To fulfill user requirements, new functionalities and capabilities such as auto-scaling, service discovery, load balancing, and permission management are constantly introduced. The introduction of these new features adds to the complexity of the system. Despite the availability of various automation methods, over time, the exponential growth in the number of different resource types, potential settings for these resource types, and the complex relationships between them pose challenges.
- Complex configuration and management requirements: As applications scale, configuring and managing Kubernetes and cloud APIs becomes increasingly complex. This includes managing a large number of container instances and resources, configuring intricate networking and storage setups, ensuring high availability and load balancing, and repetitive configurations for different environments and topologies. These complex configuration and management requirements contribute to the overall complexity of Kubernetes and cloud APIs, sometimes leading to the emergence of "YAML engineers" as a joking reference.
Despite the increasing complexity of Kubernetes and cloud APIs, they provide powerful functionalities and flexibility to help organizations effectively manage and scale their applications. By utilizing appropriate tools, engineering practices, and methods, this complexity can be alleviated, enabling efficient utilization of these technologies to meet business needs. Dynamic configuration management techniques are one of the approaches that can help address the complexity of Kubernetes and cloud APIs to a certain extent.
What is Dynamic Configuration Management
We follow the original definition of Dynamic Configuration Management (DCM) by its creator Chris Stephenson and extend it to a certain extent.
Dynamic Configuration Management (DCM) is an approach to constructing the configuration of computational workloads. Developers create workload specifications that describe everything necessary for the workload to run successfully. These specifications are used to dynamically generate configurations for deploying the workload in specific environments. With DCM, developers do not need to define or maintain environment-specific configurations for their workloads.
Dynamic Configuration Management means that developers describe the relationship between their workloads and resources in an abstract and environment-agnostic manner. They describe this relationship in a format called a workload specification or application-centric specification. The specification is generic and works across environments, which means it doesn't provide enough information to configure the workloads and resources themselves. To obtain executable configurations, we need to apply the specification to configuration baselines (for application and infrastructure configurations) and generate them based on the deployment context. For developers, Dynamic Configuration Management requires providing an application-centric configuration interface that they can understand. For platform engineers, Dynamic Configuration Management can help define how to handle configuration resources and workload specifications, leading to improved consistency and compliance within the organization. It also makes it easier to provide a self-service Internal Developer Platform (IDP).
In contrast to dynamic configuration management, static configuration management brings about a series of issues:
- Configuration Bloat: Most static configurations require separate configurations for each environment, and in the worst case, it can introduce difficult-to-debug errors involving cross-linking between environments, leading to poor stability and scalability.
- Configuration Drift: Managing application and infrastructure configurations for different environments with static management approaches often lacks standardized methods for handling dynamic variations in configurations across environments. Employing non-standardized approaches can result in exponential complexity and lead to configuration drift.
Why Do We Need a New Paradigm
Just as music is recorded on musical sheets and time-series data is stored in time-series databases, a set of configuration and policy languages is used for writing and managing scalable and complex configurations and policies in the specific problem domain of platform engineering. Unlike high-level general-purpose languages with mixed paradigms and mixed engineering capabilities, these domain-specific languages are built upon a converged, finite syntax and semantic set to tackle the near-infinite variations and complexities of the domain's problems, consolidating the mindset and approach to writing complex configurations and policies into the language's features.
For cloud APIs, we can leverage Infrastructure as Code (IaC) tools like Terraform to obtain a vast library of pre-written module configurations. However, when it comes to Kubernetes, there is still a lack of lightweight client-side configuration composition and abstraction solutions. Existing solutions or specifications struggle to strike a balance between abstraction capabilities and scalability. In extreme scenarios, developers often resort to writing glue code and scripts to handle configuration processing logic, which hinders stability and efficiency. For instance, although tools like Helm Chart provide template programming, the programming experience and efficiency are subpar. Additionally, when users need to dynamically adjust dependencies on values.yaml parameters in Helm Charts or encounter upstream Helm Charts that don't support the required parameter settings, they often resort to forking and maintaining the upstream Helm Charts in an intrusive manner or supplementing with tools like Kustomize, incurring additional maintenance costs and complexities.
Therefore, we contemplate the need for a unified specification that can simultaneously support configuration language capabilities and, with minimal side effects, fulfill the requirements of stability, scalability, and efficiency in the context of scalable configuration scenarios. This specification should also address the problems inherent in static configuration management.
- Abstraction and Composition Capabilities: By providing a programmable schema, the platform personnel can shield the underlying infrastructure details and platform, while offering developers a better and more stable API abstraction.
- Stability: By providing stable features out-of-the-box, such as rule writing and static typing, the specification enables risk mitigation and early error detection in version control systems (VCS), allowing for auditing, traceability, and rollback, and facilitating automation.
- Scalability: Similar to the application software supply chain, infrastructure configuration should be treated as part of the software supply chain. Users can distribute and reuse configurations in a standardized manner, easily accessing commonly used configurations in the open-source world. For internal platforms, we can easily write and extend configuration code.
- High performance: Since dynamic configuration management advocates generating configurations for different environments and topologies based on a baseline configuration and deployment context, there is a high demand for the rendering performance of the configuration code itself. Developers typically do not want to spend several minutes waiting for the actual configuration output, as it would hinder software iteration and upgrade efficiency.
KRM KCL Specification
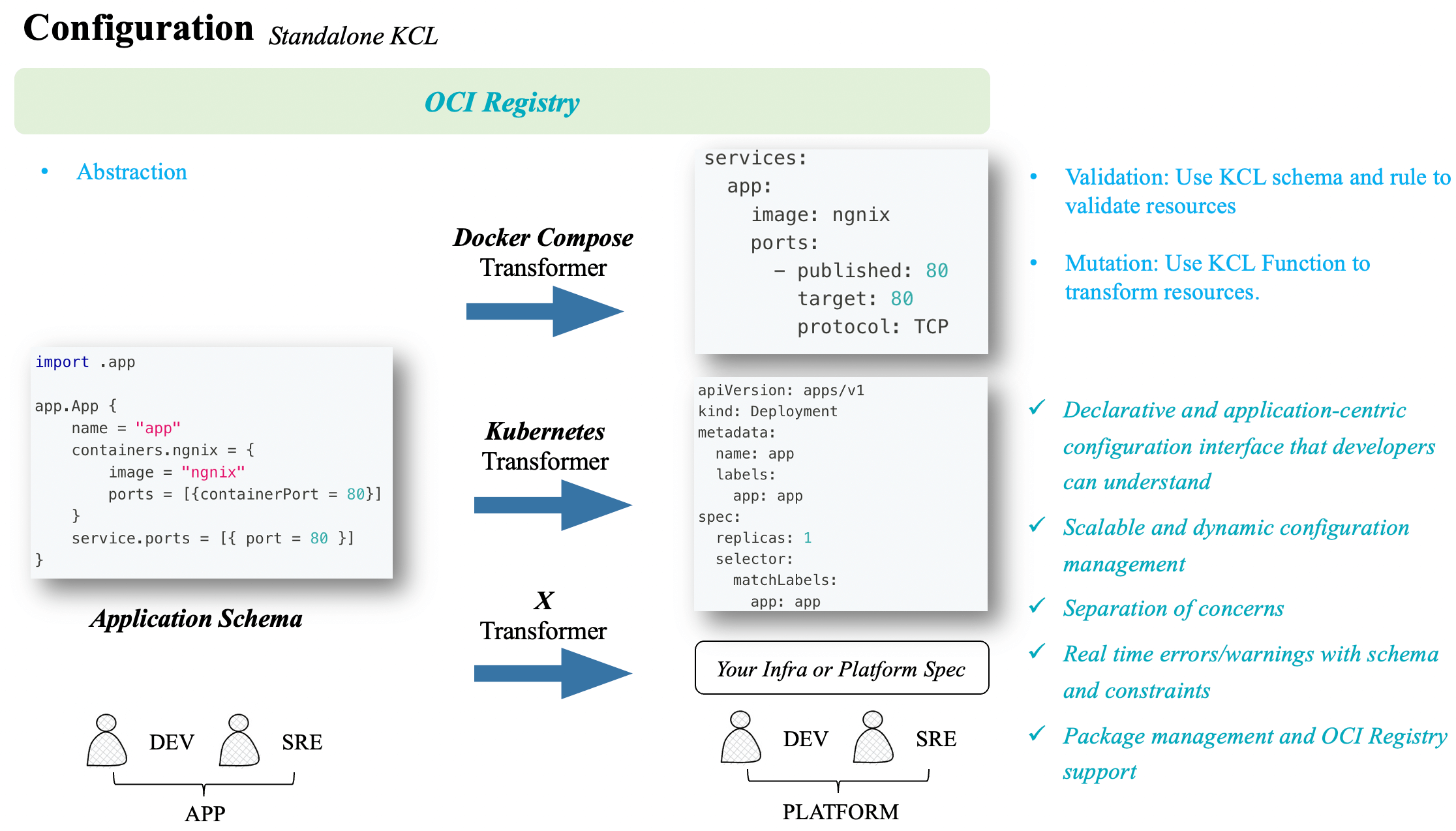
The KRM KCL specification is a configuration specification based on the Kubernetes Resource Model (KRM). KRM is a universal configuration model used to describe and manage various cloud-native resources such as containers, pods, and services. It provides a unified way to define and manage these resources, enabling portability and reuse across different environments. It exists within the open Kubernetes ecosystem, decoupled from any specific orchestration/engine tools or Kubernetes controllers. It allows platform personnel to extend their abstractions, configuration editing, and validation logic, while also enabling direct reuse of existing model abstractions from the community, such as the Open Application Model (OAM), which also complies with the KRM specification.
The KCL programming language is a core component of the KRM KCL specification. KCL is a declarative configuration language that allows users to describe the configuration requirements of their applications and associate them with underlying infrastructure. KCL has a rich syntax and semantics that can flexibly describe various configuration needs, such as environment variables, resource limits, dependencies, and more. KCL aims to hide the details of infrastructure and platforms by defining API abstractions, reducing the burden, and managing large-scale configurations across teams without side effects. It provides capabilities to write, combine, and abstract configuration blocks, such as structural definitions, constraints, and logic. In platform engineering practices, KCL is not just a key-value language but a domain-specific language tailored for the platform engineering field.
Another important feature of the KRM KCL specification is its support for dynamic configuration management. Traditional configuration management tools often rely on static configuration files that require manual modifications and deployments. The KRM KCL specification naturally provides a way to automatically modify configurations, which can be used standalone on the client-side or integrated with Kubernetes through the KCL Operator to achieve runtime configuration modifications without the need for developing Kubernetes webhooks or writing extensive configuration processing logic.
In addition to dynamic configuration management, the KRM KCL specification offers several other advantages. Firstly, it is based on Kubernetes and seamlessly integrates with the existing Kubernetes ecosystem. Secondly, the KRM KCL specification provides a rich set of tools and libraries that make it easy for developers to create, test, and maintain configurations. Lastly, the KRM KCL specification adopts open standards, allowing for interoperability with other configuration management tools such as Kubectl, Helm, Kustomize, and more. It possesses the following characteristics:
- Declarative: Configurations are abstracted and organized in code form, allowing users to view and edit them using editors or IDEs. The code clearly describes various aspects of resources, services, networks, and more.
- Final-state oriented: It is abstracted and implementation-agnostic, with highly abstracted and domain-specific underlying capabilities. The concrete business logic is written by users in a declarative manner. Users can avoid manual operations and non-uniform patterns introduced by private scripts through a unified description code and GitOps workflow, reducing security risks.
- Stability: Any modification to configuration code can potentially result in unexpected outcomes, exceptions, or failures. By combining version control and the stability features of the language itself, different versions of configuration code can be switched as needed through Git, with audibility, to meet the needs of development, testing, and production stages. For example, rolling back to a verified version in case of anomalies. Code-based version control effectively prevents configuration drift.
- Reusable and extensible: Configuration code often exhibits the characteristic of "write once, reuse multiple times". When combined with dynamically parameterized configuration code, the reuse of configurations in different environments and for different users becomes simple. Through integration with standard software supply chains such as OCI, configuration code is treated equally with business code, better achieving Infrastructure as Code (IaC).
In summary, the KRM KCL specification presents a new paradigm for dynamic configuration management. Built upon KRM and KCL, it offers a more efficient and reliable configuration solution for modern software development. With its dynamic configuration management capabilities, flexible syntax and semantics, and integration with Kubernetes, the KRM KCL specification provides developers with an enhanced configuration management experience in cloud-native application development and microservices architectures.
How to

In the KRM KCL specification, we categorize the behaviors of the KCL configuration model into three main types:
- Mutation: Takes input KCL parameters params and a KRM list, and outputs a modified KRM list.
- Validation: Takes input KCL parameters params and a KRM list, and outputs a KRM list and resource validation results.
- Abstraction: Takes input KCL parameters params and outputs a KRM list.
Using KCL, we can programmatically achieve the following capabilities:
- Modify resources using KCL, such as adding/modifying label tags or annotation comments based on certain conditions, or injecting sidecar container configurations into all Kubernetes Resource Model (KRM) resources that contain PodTemplates.
- Validate all KRM resources using KCL schemas, such as constraints for launching containers only in a root manner.
- Generate KRM resources using an abstraction model or combine and use different KRM APIs.
Additionally, the configuration model source can reference OCI, Git, filesystem, and the original KCL code. With the help of KCL IDE and KPM package management tool, we can write models and upload them to OCI Registry for model reuse. These models can be used separately on the client-side or at runtime, depending on the specific scenario requirements.
Client-side
We will use a classic web service workload as an example to demonstrate the usage of the KRM KCL specification on the client-side.
In addition, we provide plugin support for Kubernetes community configuration management tools such as Kubectl, Helm, Kustomize, KPT, etc., in a unified programming interface. With just a few lines of configuration code, you can non-invasively edit and validate existing Kustomize YAML files, Helm Charts, define your own abstraction models, and share and reuse them.
Here, we will provide a detailed explanation using the integration of KCL with the Kubectl tool as an example. You can find the installation instructions for the Kubectl KCL plugin at here.
First, execute the following command to get a sample configuration:
git clone https://github.com/kcl-lang/kubectl-kcl.git && cd ./kubectl-kcl/examples/
Then, execute the following command to show the configuration:
$ cat krm-kcl-abstraction.yaml
apiVersion: krm.kcl.dev/v1alpha1
kind: KCLRun
metadata:
name: web-service
spec:
params:
name: app
containers:
nginx:
image: nginx
ports:
- containerPort: 80
service:
ports:
- port: 80
source: oci://ghcr.io/kcl-lang/web-service
In the above configuration, we use a pre-defined Kubernetes web service application abstraction model oci://ghcr.io/kcl-lang/web-service on the OCI registry, and configure the required fields for that model through the params field. By executing the following command, you can obtain the raw Kubernetes YAML output and deploy it to the cluster:
$ kubectl kcl apply -f krm-kcl-abstraction.yaml
deployment.apps/app created
service/app created
In addition to using YAML as the user input interface, KCL can be used as a DSL for writing configurations and policies. It allows developers and platform personnel to write and maintain configurations on a large scale using a unified KCL writing style on the client-side.
Runtime
At runtime, we provide Kubernetes cluster integration through the KCL Operator, allowing you to generate, mutate, or validate resources based on KCL configurations using an Access Webhook when applying resources to the cluster. The webhook captures create, apply, and edit operations and executes resources on the configuration associated with each operation using the KCLRun resource. With the KCL Operator, you can automate resource configuration management and security validation in a lightweight manner within a Kubernetes cluster using KCL code, without the need to develop a webhook server to dynamically modify and validate configurations at runtime.
Additionally, leveraging the modeling and abstraction capabilities of KCL, we can define functional abstractions/compositions for different resource APIs and expose them in the form of KCL schemas. Moreover, KCL schemas can be further automatically generated into OpenAPI schema definitions for other clients in the cluster to call, without the need for manually maintaining complex OpenAPI schema definitions for API abstractions/compositions.
Here is an example of using the KCL Operator to modify resource annotations.
Install the KCL Operator:
kubectl apply -f https://raw.githubusercontent.com/kcl-lang/kcl-operator/main/config/all.yaml
Use the following command to observe and wait for the pod status to be Running:
kubectl get po
Deploy the annotation mutation model:
kubectl apply -f- << EOF
apiVersion: krm.kcl.dev/v1alpha1
kind: KCLRun
metadata:
name: set-annotation
spec:
params:
annotations:
managed-by: kcl-operator
source: oci://ghcr.io/kcl-lang/set-annotation
EOF
Deploy a Pod resource to validate the model result:
kubectl apply -f- << EOF
apiVersion: v1
kind: Pod
metadata:
name: nginx
annotations:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
EOF
kubectl get po nginx -o yaml | grep kcl-operator
We can see the following output:
managed-by: kcl-operator
We can observe that the Nginx Pod automatically added the annotation managed-by=kcl-operator.
Summary
Dynamic configuration management can reduce the complexity of modern cloud-native configurations. With the KRM KCL specification and standard OCI models, we can achieve dynamic configuration management, allowing platform personnel and application developers to easily utilize these settings and reduce cognitive load.
Resources
Reference
- Declarative Application Management in Kubernetes: https://docs.google.com/document/d/1cLPGweVEYrVqQvBLJg6sxV-TrE5Rm2MNOBA_cxZP2WU/edit#
- CNCF Platforms White Paper: https://tag-app-delivery.cncf.io/whitepapers/platforms/
- Google SRE Workbook: https://sre.google/workbook/configuration-specifics/
- What is Dynamic Configuration Management: https://humanitec.com/blog/what-is-dynamic-configuration-management
- Implementing Dynamic Configuration Management with Score and Humanitec: https://humanitec.com/blog/implementing-dynamic-configuration-management-with-score-and-humanitec
- What is Platform Engineering: https://platformengineering.org/blog/what-is-platform-engineering
- What is Internal Developer Platform: https://internaldeveloperplatform.org/what-is-an-internal-developer-platform/
- What Team Structure is Right for DevOps to Flourish: https://web.devopstopologies.com/#anti-types