Best Practice
本文档旨在讲解新的业务模型接入 Konfig 大库以及 KCL 代码模型设计与编写的最佳实践,新业务模型一般采用前-后端模型分离的最佳实践进行设计与抽象,区分前端模型和后端模型的直接目的是将「用户界面」和「模型实现」进行分离,实现用户友好的简单的配置界面以及自动化配置增删改查接口。
工作流程
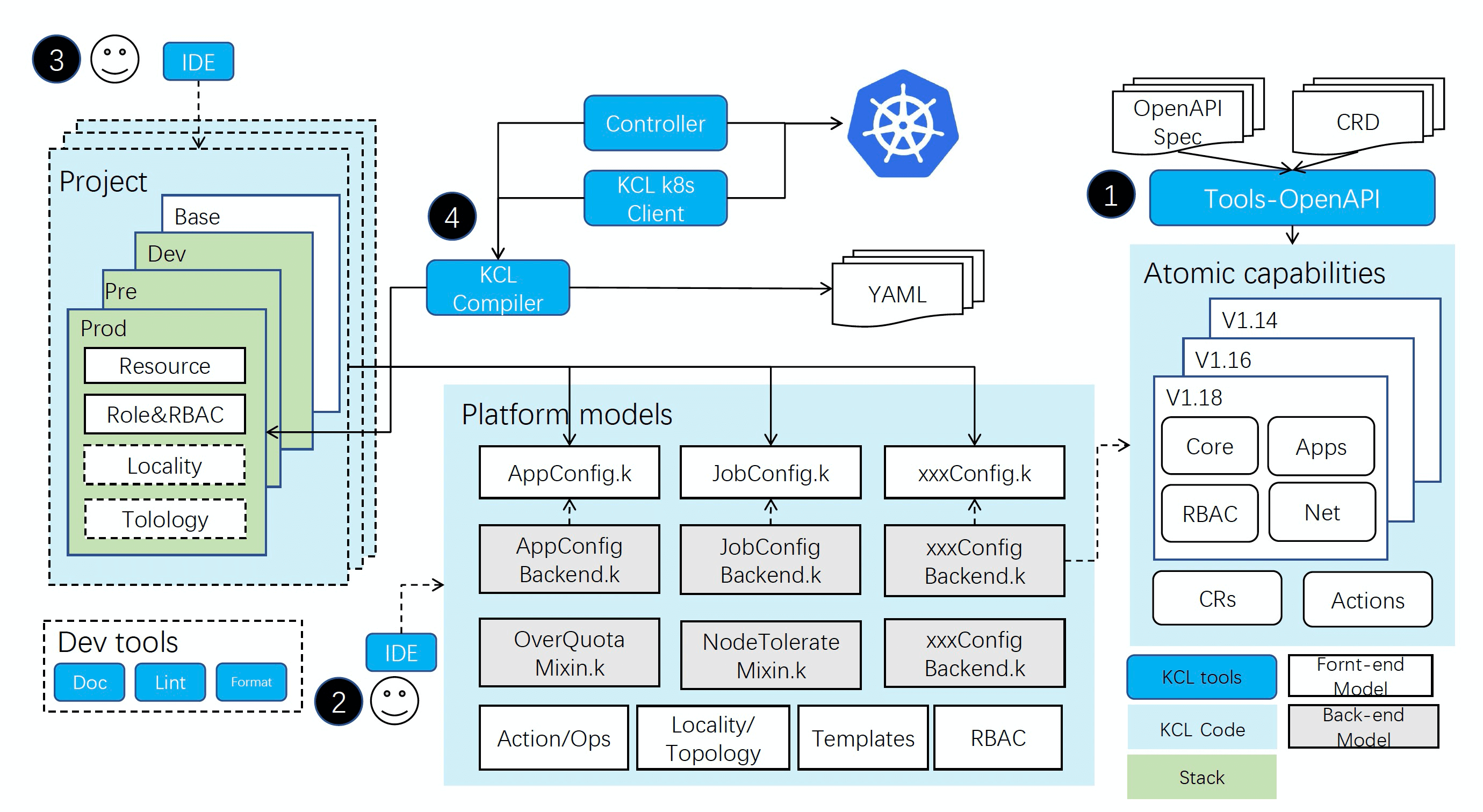
- 首先使用 KCL OpenAPI 工具生成下游所需配置的 KCL 模型代码,对于 Kubernetes 模型;可以根据 CRD 或者 Swagger Model 生成,对于其他场景,可以使用 Terraform provider schema、Java Class 或者 Go Struct 生成相应 KCL Schema (建设中),作为后端模型并存放在 "基础配置代码" 中;
- 使用 KCL 开发工具(包括 KCL 编译器、KCL format,doc,lint,test 等工具和 IDE 插件等),根据业务语义抽象前端模型;
- 依据 Project & Stack 方式在 Konfig 仓库中组织用户侧配置代码(主要是对前端模型的实例化),Konfig 会自动根据 project.yaml 和 stack.yaml 文件进行测试;
- 最后编译 KCL 代码生成 YAML,通过测试后,利用 CI/CD 流程完成配置的 diff 与分发。
模型结构
正如 web 应用会提供友好的用户界面,而在应用的后端对用户输入进行进一步推演得到最终落库的数据,类似地,使用 KCL 进行模型设计时同样遵循前后端分离的逻辑。此外当下游所需的数据内容发生变化时,我们仅需修改用户配置数据到后端模型的渲染/逻辑即可,从而避免了大规模修改用户配置的情况。以应用服务的 sidecar 配置为例,直接暴露给用户的只有 user_sidecar_feature_gates,而最终交给下游处理的数据中,则应是把 user_sidecar_feature_gates 作为 sidecars 配置的一部分包装起来的结果。比如如下代码:
# 用户可配的:
user_sidecar_feature_gates: str
# 下游能处理的:
sidecars = [
{
name = "sidecar_name" # sidecars 参数的额外模版参数,用户不需要进行配置
feature_gates = user_sidecar_feature_gates
}
]
模型抽象的最佳实践
使用一个属性代替配置模板
对于一些后端模型所需要填写的配置字段往往是大而全的设计,需要用户主动输入较为复杂的配置模版,并且不同用户对于该字段的填写内容基本一致,比如在图 1 示出的超卖逻辑的配置就需要用户填写大量的模板数据,心智成本较高,一个简单的最佳实践是对于此类常用复杂的模板在前端模型中抽象为一个简单的 bool 类型的变量 overQuota,让用户做选择题而不是填空题,比如当 overQuota 变量为 True 时,后端模型才会渲染这个复杂逻辑。
- The front-end attribute
overQuota
overQuota: bool
- The back-end YAML output:
spec:
template:
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: k8s/is-over-quota
operator: In
values:
- "true"
对于不是 True/False 属性可以选择的模版,也可以根据具体的业务场景设计不同的模版名称来填空,比如如图 2 所示的代码设计一个属性 template 来辅助用户做模版的选择而不是直接填入模板内容。合法的 template 值可以为 "success_ratio" 或者 "service_cost", 当后端模型扩展更多的模版时,前端代码无需作出任何修改,仅需在后端模型中适配相应模板逻辑即可。
schema SLI:
template: str = "success_ratio"
此外,尽量不采用复杂的结构直接作为前端模型属性,避免用户使用该模型时需要借助过多的 KCL 语法特性(比如解包、循环等特性)或者书写很多临时变量完成该结构的实例化。
使用字面值类型
在上述小节提到了可以使用一个字符串属性表示不同的模板名称,更进一步地是可以使用字面值类型表述 template 可选的内容,比如可以进行如下改进。
schema SLI:
template: "success_ratio" | "service_cost" = "success_ratio"
其中 template 的类型为两个字符串类型的联合,表示 template 只能为 "success_ratio" 或者 "service_cost",当用户填写了其他字符串的值时,KCL 编译器会进行报错。
使用联合类型
除了对字面值类型使用联合类型外,KCL 还支持对复杂类型如 schema 类型的联合。对于这种后端 oneof 配置的支持,KCL 内置了复合结构的联合类型进行支持。比如我们可以针对多种种场景定义自己的 SLI 前端类型:CustomSliDataSource,PQLSLIDataSource 和 StackSLIDataSource。
schema CustomSLIDataSource:
customPluginUrl: str
schema PQLSLIDataSource:
total?: str
error?: str
success?: str
cost?: str
count?: str
schema StackSLIDataSource:
stack: str
groupBy?: str
metric?: str
# Simplify type definitions using type aliases
type DataSource = CustomSLIDataSource | PQLSLIDataSource | StackSLIDataSource
schema DataConfiguration:
sources: {str: DataSource}
这样前端模型设计的好处是编译器可以静态地检查出用户书写的类型只能是某一种类型,如果直接使用后端模型无法从模型上直接获得不同类型 type 与需要填写字段的映射关系。
此外,前端模型的整体设计上也应该考虑横向扩展性,尽可能地采用联合类型,充分利用代码化的优势,避免对接不同后端或者后端模型发生改变时带来不必要的大量代码前端代码与用户代码重构与修改。此外,对于其他 GPL 语言中常用的工厂模式,在 KCL 中也可以使用联合类型代替,比如想要根据某个字符串内容获得某个类型的构造函数,可以直接使用联合类型进行优化。
KCL 中书写工厂模式
schema DataA:
id?: int = 1
value?: str = "value"
schema DataB:
name?: str = "DataB"
_dataFactory: {str:} = {
DataA = DataA
DataB = DataB
}
dataA = _dataFactory["DataA"]()
dataB = _dataFactory["DataB"]()
使用联合类型替换工厂模式
schema DataA:
id?: int = 1
value?: str = "value"
schema DataB:
name?: str = "DataB"
# 直接使用联合类型即可
dataA: DataA | DataB = DataA()
dataB: DataA | DataB = DataB()
列表/数组属性字典化
为了便于作配置的原地修改或者程序自动化查询修改,尽量将列表/数组属性定义为字典类型方便索引,因为在大部分配置场景对于复杂结构的列表类型,列表的索引 0, 1, 2, ..., n 不具备任何业务含义,列表中元素的顺序对该列表配置无任何影响,此时采用字典类型而不是列表类型更方便数据的查询与修改。首先以一个简单例子举例:
schema Person:
name: str
age: int
schema House:
persons: [Person]
house = House {
persons = [
Person {
name = "Alice"
age = 18
}
Person {
name = "Bob"
age = 10
}
]
}
比如在上述例子中,想要查询 name 为 "Alice" 的年龄 age, 就需要在 house.persons 这个列表中作遍历才能很查询到 Alice 的 age。而将 persons 定义为如下代码所示的字典,不仅从代码上看起来更加简洁,并且可以通过 house.persons.Alice.age 直接获得 Alice 的 age,并且整个配置的信息完整且无冗余信息。
schema Person:
age: int
schema House:
persons: {str: Person} # 将 persons 定义为字典而不是数组
house = House {
persons = {
Alice = Person { age = 18 }
Bob = Person { age = 10 }
}
}
为模型书写校验表达式
对于前端模型,往往需要对用户填写的字段进行校验,此时可以使用 KCL 的 check 表达式与 KCL 的内置函数/语法/系统库进行配合对字段进行校验。对于前端模型的校验尽可能直接书写在前端模型的定义中进行校验前置,避免错误传递到后端模型中发生意想不到的错误。
使用 all/any 表达式与 check 表达式进行校验
import regex
schema ConfigMap:
name: str
data: {str:str}
configMounts?: [ConfigMount]
check:
all k in data {
regex.match(k, r"[A-Za-z0-9_.-]*")
}, "a valid config key must consist of alphanumeric characters, '-', '_' or '.'"
schema ConfigMount:
containerName: str
mountPath: str
subPath?: str
check:
":" not in mountPath, "mount path must not contain ':'"
使用数值单位类型
KCL 中带单位的数字具有一个内置的类型 units.NumberMultiplier, 不允许进行任意四则运算。
import units
type NumberMultiplier = units.NumberMultiplier
x0: NumberMultiplier = 1M # Ok
x1: NumberMultiplier = x0 # Ok
x2 = x0 + x1 # Error: unsupported operand type(s) for +: 'number_multiplier(1M)' and 'number_multiplier(1M)'
可以使用 int()/float() 函数和 str() 函数将数字单位类型转换为整数类型或者字符串类型,产生的字符串保留原有数字单位类型的单位。
a: int = int(1Ki) # 1024
b: str = str(1Mi) # "1Mi"
对于在 Konfig 中的 Kubernetes Resource 资源相关的定义均可使用数值单位类型进行书写
import units
type NumberMultiplier = units.NumberMultiplier
schema Resource:
cpu?: NumberMultiplier | int = 1
memory?: NumberMultiplier = 1024Mi
disk?: NumberMultiplier = 10Gi
epchygontee?: int
前端模型实例的自动化修改
在 KCL,可以通过命令行和 API 界面实现对前端模型实例的自动化修改,比如想要修改某个应用(Konfig Stack Path: appops/nginx-example/dev)配置的镜像内容,可以直接执行如下指令修改镜像
kcl -Y kcl.yaml ci-test/settings.yaml -o ci-test/stdout.golden.yaml -d -O :appConfiguration.image=\"test-image-v1\"
更多与自动化相关的使用文档请参考 自动化 一节
使用函数
# Define a function that adds two numbers and returns the result。
add = lambda x, y {
x + y
}
# Define a function that subs two numbers and returns the result。
sub = lambda x, y {
x - y
}
# Call the function, pass in arguments, and obtain the return value.
result = sub(add(2, 3), 2) # The result is 3.
输出 YAML 为:
result: 3
使用代码包
创建一个名为 utils.k 的包,在其中定义一个名为 KCL 函数 add,并将其导入另一个文件中使用。
utils.k
# utils.k
# Define a function that adds two numbers and returns the result。
add = lambda x, y {
x + y
}
# Define a function that subs two numbers and returns the result。
sub = lambda x, y {
x - y
}
main.k
# main.k
import .utils
# Call the function, pass in arguments, and obtain the return value.
result = utils.sub(utils.add(2, 3), 2) # The result is 3.
使用配置简化逻辑表达式
# Complex Logic, `_cpu` is a non-exported and mutable attribute.
_cpu = 256
_priority = "1"
if _priority == "1":
_cpu = 256
elif _priority == "2":
_cpu = 512
elif _priority == "3":
_cpu = 1024
else:
_cpu = 2048
# Simplify Logic Expression using Config
cpuMap = {
"1" = 256
"2" = 512
"3" = 1024
}
# Get cpu from the cpuMap, when not found, use the default value 2048.
cpu = cpuMap[_priority] or 2048
输出 YAML 为:
cpuMap:
"1": 256
"2": 512
"3": 1024
cpu256: 256
cpu2048: 2048
分离逻辑和数据
我们可以使用 KCL schema、config 和 lambda尽可能多地分离数据和逻辑。
比如我们可以编写如下代码 (main.k)
schema Student:
"""Define a `Student` schema model with documents.
Attributes
----------
name : str, required
The name of the student.
id : int, required.
The id number of the student.
grade : int, required.
The grade of the student.
Examples
--------
s = Student {
name = "Alice"
id = 1
grade = 80
}
"""
name: str
id: int
grade: int
# Define constraints for the `Student` model.
check:
id >= 0
0 <= grade <= 100
# Student data.
students: [Student] = [
{name = "Alice", id = 1, grade = 85}
{name = "Bob", id = 2, grade = 70}
{name = "Charlie", id = 3, grade = 90}
{name = "David", id = 4, grade = 80}
{name = "Eve", id = 5, grade = 95}
]
# Student logic.
query_student_where_name = lambda students: [Student], name: str {
# Query the first student where name is `name`
filter s in students {
s.name == name
}?[0]
}
alice = query_student_where_name(students, name="Alice")
bob = query_student_where_name(students, name="Bob")
输出 YAML 为:
students:
- name: Alice
id: 1
grade: 85
- name: Bob
id: 2
grade: 70
- name: Charlie
id: 3
grade: 90
- name: David
id: 4
grade: 80
- name: Eve
id: 5
grade: 95
alice:
name: Alice
id: 1
grade: 85
bob:
name: Bob
id: 2
grade: 70
为模型添加代码注释
为便于用户理解以及模型文档自动生成,需要对定义的模型编写注释,注释内容一般包括模型的解释,模型字段的解释,类型,默认值,使用样例等。详细的 KCL Schema 代码注释编写规范以及模型文档自动生成可以参考 KCL 文档规范。并且我们可以使用 kcl-doc generate 命令从用户指定的文件或目录中提取文档,并将其输出到指定的目录。
后端模型
后端模型是「模型实现」,主要包括将前端模型映射为后端模型的逻辑代码。当编写完成前端模型后,我们可以使用前端模型 Schema 新建前端模型的实例 instance 并编写相应的后端映射/渲染代码将这些前端 instance 转换为后端模型,并且利用 KCL 多文件编译和 Schema.instances() 函数可以做到前端代码和后端代码的高度解耦,用户仅需关心前端的配置而不感知模型复杂的校验、逻辑判断等代码。
kcl.yaml
在 Konfig 各个 project 各 stack 中往往存放了一个 kcl.yaml 文件,kcl.yaml 文件是 KCL 进行编译所需要的配置文件,其中主要放置了编译该 stack 所需要的 KCL 文件,以 https://github.com/KusionStack/konfig/blob/main/appops/nginx-example/dev/kcl.yaml 文件为例:
kcl_cli_configs:
files:
- ${KCL_MOD}/base/pkg/kusion_models/kube/metadata/metadata.k
- ../base/base.k
- ./main.k
- ${KCL_MOD}/base/pkg/kusion_models/kube/render/render.k
${KCL_MOD}表示 Konfig 根目录 kcl.mod 文件所在的路径- metadata_render.k 预先定义一些常量用户使用,针对不同的场景可以不同,非必须
- base.k 应用的基线配置,使用前端模型生成相应 instance,非必须
- main.k 应用的环境配置,使用前端模型生成相应 instance
- render.k 后端代码,负责拿到用户前端 instance 作模型渲染