
前言
KubeVela 是一个 CNCF 基金会托管的现代的应用交付系统,它基于 Open Application Model(OAM)规范构建,旨在屏蔽 Kubernetes 的复杂性,提供一套简单易用的命令行工具和 APIs,让开发者无需关心底层细节即可部署和运维云原生应用。
KCL 是一个 CNCF 基金会托管的面向云原生场景的配置及策略语言,期望通过成熟的编程语言技术和实践来改进对大量繁杂配置比如云原生 Kubernetes 配置场景的编写,致力于构建围绕配置的更好的模块化、扩展性和稳定性,更简单的逻辑编写,以及更简单的自动化和生态工具集成。
KCL 建立在一个完全开放的云原生世界当中,不与任何编排/引擎工具或者 Kubernetes 控制器绑定,可以同时为 Kubernetes 客户端和运行时提供 API 抽象、组合和校验的能力。
用户可以根据场景选择合适的云原生工具比如 Kubectl, Helm, Kustomize, KPT, KusionStack, KubeVela, Helmfile, Crossplane 或 ArgoCD 等来和 KCL 结合将配置生效到集群。

本篇文章是将 KCL 与 KubeVela 一起使用实现高效云原生应用部署运维的系列文章第一篇,后续我们会分享更多高级用法,尽情期待。
将 KCL 与 KubeVela 一起使用
将 KCL 与 KubeVela 一起使用具有如下好处:
- 更简单的配置:在客户端层面为 KubeVela OAM 配置提供更强的模版化能力如条件,循环等,减少样板 YAML 书写,同时复用 KCL 模型库和工具链生态,提升配置及策略编写的体验和管理效率。
- 更好的可维护性:通过 KCL 可以提供更有利于版本控制和团队协作的配置文件结构,而不是围绕 YAML 进行配置,同时搭配 KCL 编写的 OAM 应用模型,可以使得应用配置更易于维护和迭代。
- 更简化的操作:结合 KCL 的配置简洁性和 KubeVela 的易用性,可以简化日常的操作任务,比如部署更新、扩展或回滚应用。开发者可以更加专注于应用本身,而不是部署过程中的繁琐细节。
- 更好的跨团队协作:通过 KCL 配置分块编写以及包管理能力与 KubeVela 结合使用,可以定义更清晰的界限,使得不同的团队(如开发、测试和运维团队)可以有条理地协作。每个团队可以专注于其职责范围内的任务,分别交付、分享和复用各自的配置,而不用担心其他方面的细节。
工作流程
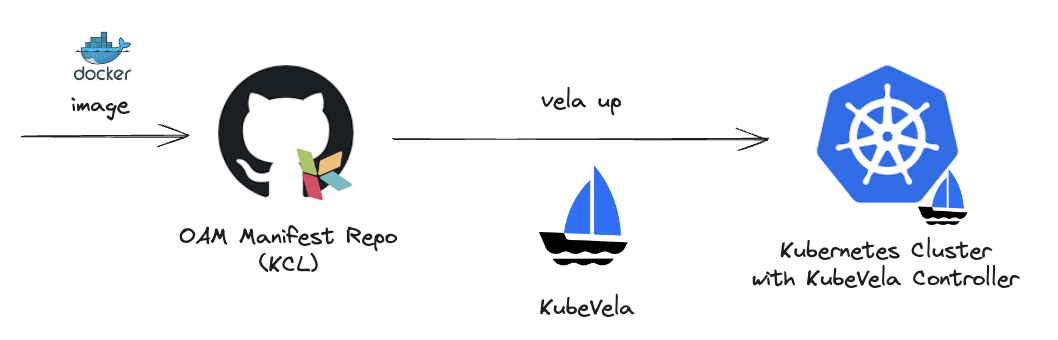
在此示例中,我们使用 KCL Playground 应用为例(这是使用 Go 和 HTML5 编写的应用),同时使用 KCL 定义需要部署的 OAM 配置
整体工作流程如下
- 应用代码开发产出 Docker 镜像
- 使用 KCL 编写 OAM 配置
- 使用 KubeVela 发布配置
- 验证应用运行情况
具体步骤
0. 先决条件
- 熟悉 Unix/Linux 的基本命令
- 熟悉 Git 使用
- 了解 Kubernetes 基本知识
- 了解 KubeVela
- 了解 KCL 基本知识
1. 配置 Kubernetes 集群
- 安装 K3d 并创建一个集群
k3d cluster create
注意:你可以在此方案中使用其他方式创建您自己的 Kubernetes 集群,如 kind, minikube 等。
2. 安装 KubeVela
- 安装 KubeVela CLI
curl -fsSl https://kubevela.net/script/install.sh | bash
- 安装 KubeVela Core
vela install
3. 安装 KCL 并编写配置
- 安装 KCL
curl -fsSL https://kcl-lang.io/script/install-cli.sh | /bin/bash
- 新建工程并添加 OAM 依赖
kcl mod init kcl-play-svc && cd kcl-play-svc && kcl mod add oam
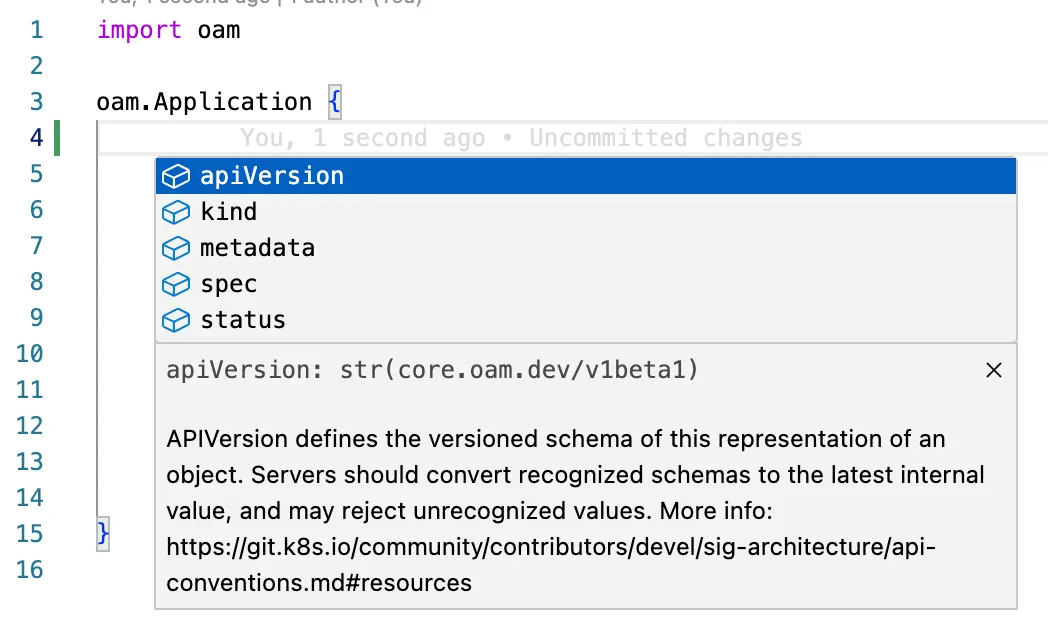
- 在 main.k 中编写如下代码
import oam
oam.Application {
metadata.name = "kcl-play-svc"
spec.components = [{
name = metadata.name
type = "webservice"
properties = {
image = "kcllang/kcl:v0.9.0"
ports = [{port = 80, expose = True}]
cmd = ["kcl", "play"]
}
}]
}
注意,你可以在 ArtifactHub 上查阅到相应的 OAM 模型文档或者直接在 IDE 中查看 https://artifacthub.io/packages/kcl/kcl-module/oam or in the IDE extension.
4. 部署应用并验证
- 下发配置
kcl run | vela up -f -
- 端口转发
vela port-forward kcl-play-svc
然后我们可以在浏览器中看到 KCL Playground 应用成功运行
结论
通过本篇文章的教程,我们可以使用 KubeVela 和 KCL 等初步部署云原生应用,后续我们将通过更多文章讲解如何在客户端使用 KCL 进一步扩展 KubeVela 的能力
- 使用 KCL 的继承、组合和校验手段扩展 OAM 模型,比如根据您的基础设施或者组织基于 OAM 定义更适合的应用抽象模型
- 使用 KCL 配置分块编写,条件,逻辑,循环和模块化能力更好地组织 OAM 多环境配置,提升模版化能力,比如将较长的 App Definition 分散到不同的文件进行组织,减少样板配置
- 与 KusionStack 和 ArgoCD 等项目进一步集成实现更好的 GitOps
- 将更多的云原生能力或 Kubernetes Operator 如 KubeBlocks 和 Crossplane 等实现更好的数据库运维以及统一的云 API 和 Kubernetes API 可编程接入
- 其他更多使用场景...